
Алгоритм RANSAC
RANSAC ( английский побежал дом са mple с onsensus , немецкий как «матч с случайной выборки») является повторной дискретизации - алгоритм для оценки модели внутри серии измерений с выбросами и грубых ошибок . Благодаря своей устойчивости к выбросам, он в основном используется для оценки автоматических измерений в области компьютерного зрения . Здесь RANSAC поддерживает - путем вычисления объема данных с поправкой на выбросы, так называемый набор консенсуса - процедуры компенсации, такие как метод наименьших квадратов , который обычно терпит неудачу при большом количестве выбросов.
RANSAC был официально представлен в 1981 году Мартином А. Фишлером и Робертом Боллсом в сообщениях ACM . Внутренняя презентация в SRI International , над которой работали оба автора, состоялась в марте 1980 года. М-оценки являются альтернативой RANSAC . По сравнению с другими оценками, такими как оценки максимального правдоподобия, они более устойчивы к выбросам.
Введение и принцип
Результатом измерения часто являются точки данных, которые представляют физические величины, такие как давление, расстояние или температура, экономические параметры и т.п. В эти точки следует поместить кривую модели, зависящую от параметров, которая подходит как можно точнее. Доступно больше точек данных, чем необходимо для определения параметров; так что модель переопределена . Измеренные значения могут содержать выбросы, то есть значения, которые не укладываются в ожидаемую серию измерений . Поскольку до появления цифровых технологий измерения в основном выполнялись вручную, контроль со стороны хирурга означал, что доля выбросов обычно была низкой. Используемые в то время алгоритмы компенсации , такие как метод наименьших квадратов, хорошо подходят для оценки таких наборов данных с небольшим количеством выбросов: с их помощью сначала определяется модель со всеми точками данных, а затем делается попытка. сделано для обнаружения выбросов.

С развитием цифровых технологий с начала 1980-х годов основы изменились. Благодаря новым возможностям, все чаще использовались автоматические методы измерения, особенно в области компьютерного зрения . В результате часто получается большое количество значений, которые обычно содержат много выбросов. Традиционные методы предполагают нормальное распределение ошибок и иногда не дают значимого результата, если точки данных содержат много выбросов. Это показано на иллюстрации напротив. Прямая линия (модель) должна быть адаптирована к точкам (измеренным значениям). С одной стороны, нельзя исключить отдельные выбросы среди 20 точек данных, используя традиционные методы до определения прямой линии. С другой стороны, из-за своего положения он оказывает непропорционально сильное влияние на линию регрессии (так называемую точку плеча).
Алгоритм RANSAC следует новому итеративному подходу. Вместо уравнивания всех измеренных значений вместе используется только столько случайно выбранных значений, сколько необходимо для расчета параметров модели (в случае прямой линии это будут две точки). Первоначально предполагается, что выбранные значения не являются выбросами. Это предположение проверяется путем сначала расчета модели на основе случайно выбранных значений, а затем определения расстояния всех измеренных значений (то есть не только первоначально выбранных) до этой модели. Если расстояние между измеренным значением и моделью меньше, чем ранее определенное пороговое значение, то это измеренное значение не является грубой ошибкой по отношению к рассчитанной модели. Так что он поддерживает это. Чем больше измеренных значений поддерживает модель, тем более вероятно, что значения, случайно выбранные для расчета модели, не содержат выбросов. Эти три шага - случайный выбор измеренных значений, расчет параметров модели и определение опоры - повторяются несколько раз независимо друг от друга. На каждой итерации сохраняется, какие измеренные значения поддерживают соответствующую модель. Этот набор называется набором консенсуса . На основе наибольшего согласованного набора , который в идеале больше не содержит выбросов, решение затем определяется с использованием одного из традиционных методов корректировки.
Приложения
Как уже упоминалось, многие выбросы в основном возникают при автоматических измерениях. Они часто выполняются в области компьютерного зрения , поэтому RANSAC здесь особенно распространен. Некоторые приложения представлены ниже.

При обработке изображений RANSAC используется для определения точек гомологии между изображениями с двух камер. Две точки изображения, которые одна точка объекта создает на двух изображениях, гомологичны. Назначение гомологических точек называется проблемой соответствия. Результат автоматического анализа обычно содержит большое количество неверных назначений. Процедуры, основанные на результатах анализа соответствий, используют RANSAC для исключения неверных назначений. Примером такого подхода является создание панорамного изображения из различных более мелких отдельных изображений ( склейка ). Другой - расчет эпиполярной геометрии . Это модель из геометрии, которая показывает геометрические отношения между изображениями одного и того же объекта с разных камер. Здесь RANSAC используется для определения фундаментальной матрицы, описывающей геометрические отношения между изображениями.
В DARPA Grand Challenge , соревновании для автономных наземных транспортных средств, RANSAC использовался для определения дорожного покрытия и реконструкции движения транспортного средства.
Алгоритм также используется для адаптации геометрических тел, таких как цилиндры и т.п., в зашумленные трехмерные наборы точек или для автоматического сегментирования облаков точек . Все точки, которые не принадлежат одному сегменту, рассматриваются как выбросы. После оценки наиболее доминирующего тела в облаке точек все точки, принадлежащие этому телу, удаляются, чтобы на следующем шаге можно было определить другие тела. Этот процесс повторяется до тех пор, пока не будут найдены все тела в наборе точек.
Порядок действий и параметры
Предварительным условием для RANSAC является наличие большего количества точек данных, чем необходимо для определения параметров модели. Алгоритм состоит из следующих шагов:
- Произвольно выберите столько точек из точек данных, сколько необходимо для расчета параметров модели. Это сделано в ожидании того, что в этом наборе не будет выбросов.
- Определите параметры модели с выбранными точками.
- Определите подмножество измеренных значений, расстояние от которого до модельной кривой меньше определенного предельного значения (это подмножество называется согласованным набором ). Если он содержит определенное минимальное количество значений, вероятно, была найдена хорошая модель, и набор консенсуса сохранен.
- Повторите шаги 1-3 несколько раз.
После выполнения нескольких итераций выбирается то подмножество, которое содержит наибольшее количество точек (если таковая была найдена). Параметры модели рассчитываются одним из обычных методов компенсации только с этим подмножеством. Альтернативный вариант алгоритма преждевременно завершает итерации, если достаточное количество точек поддерживает модель на шаге 3. Этот вариант называется упреждающим - т.е. преждевременным завершением - RANSAC. При таком подходе необходимо заранее знать, насколько велика доля выбросов, чтобы можно было оценить, поддерживают ли модели достаточные измеренные значения.
Алгоритм существенно зависит от трех параметров:
- максимальное расстояние точки данных от модели, до которого точка не считается грубой ошибкой;
- количество итераций и
- минимальный размер набора консенсуса , то есть минимальное количество точек, соответствующих модели.
Максимальное расстояние точки данных от модели
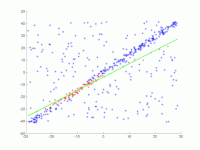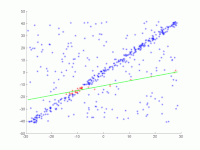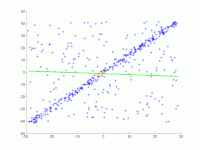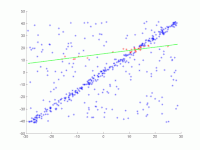
Этот параметр является основополагающим для успеха алгоритма. В отличие от двух других параметров, он должен быть указан ( согласованный набор не нужно проверять , а количество итераций можно выбрать практически неограниченным). Если значение слишком велико или слишком мало, алгоритм может дать сбой. Это показано на следующих трех рисунках. В каждом случае показан один шаг итерации. Две случайно выбранные точки, по которым была рассчитана зеленая модельная линия, окрашены в синий цвет. Эти оценки погрешностей показаны в виде черных линий. Внутри этих линий должна находиться точка, чтобы поддерживать модельный ряд. Если выбрано слишком большое расстояние, слишком много выбросов не будет распознано, так что неправильная модель может иметь такое же количество выбросов, что и правильная модель (рис. 1a и 1b). Если он установлен слишком низким, может случиться так, что модель, которая была рассчитана на основе набора значений без выбросов, поддерживается слишком небольшим количеством других значений, которые не являются выбросами (рис. 2).
- Проблемы, если выбор предела ошибки слишком велик или слишком мал

1а. Правильное решение, два пункта - выбросы.
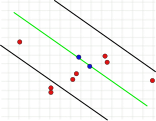
1b. Во-вторых, неправильное решение с тем же количеством выбросов, что и в 1а.
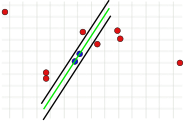
2. Граница ошибки слишком мала.



Несмотря на эти проблемы, это значение обычно необходимо определять эмпирически . Предел погрешности может быть рассчитан только с использованием законов распределения вероятностей, если известно стандартное отклонение измеренных значений .
Количество итераций
Число повторений можно установить таким образом, чтобы с определенной вероятностью из точек данных выбиралось подмножество без выбросов хотя бы один раз. Если количество точек данных, необходимых для расчета модели, и относительная доля выбросов в данных, то вероятность того, что по крайней мере один выброс не будет выбираться каждый раз в случае повторения




- ,

и поэтому вероятность того, что по крайней мере один выброс будет выбираться каждый раз, не больше , должна быть выбрана достаточно большой. Будь точнее хотя бы


Необходимы повторы. Таким образом, количество зависит только от доли выбросов, количества параметров функции модели и заданной вероятности отрисовки хотя бы одного подмножества без выбросов. Он не зависит от общего количества измеренных значений.
В таблице ниже показано необходимое количество повторений в зависимости от пропорции выбросов и количества точек, необходимых для определения параметров модели. Вероятность выбора хотя бы одного подмножества без выбросов из всех точек данных установлена на уровне 99%.
| пример | Количество требуемых баллов |
Процент выбросов | ||||||
|---|---|---|---|---|---|---|---|---|
| 10% | 20% | 30% | 40% | 50% | 60% | 70% | ||
| Просто | 2 | 3 | 5 | 7-е | 11 | 17-е | 27 | 49 |
| уровень | 3 | 4-й | 7-е | 11 | 19-е | 35 год | 70 | 169 |
| Фундаментальная матрица | 8-е | 9 | 26 | 78 | 272 | 1177 | 7025 | 70188 |

Размер согласованного набора
В общем варианте алгоритма это значение не обязательно должно быть известно, поскольку, если не проводить проверку правдоподобия, в дальнейшем можно просто использовать самый большой консенсусный набор . Однако знание этого необходимо для варианта, который прерывается преждевременно. В этом случае минимальный размер консенсусного набора обычно определяется аналитически или экспериментально. Хорошее приближение - это общее количество измеренных значений за вычетом доли отклоняющихся значений , которые предполагаются в данных. Минимальный размер такой же для точек данных . Например, при 12 точках данных и 20% выбросов минимальный размер составляет примерно 10.

Адаптивное определение параметров
Доля выбросов в общем количестве точек данных часто неизвестна. Поэтому невозможно определить необходимое количество итераций и минимальный размер согласованного набора . В этом случае алгоритм инициализируется с предположением наихудшего случая о доле выбросов, равной, например, 50%, и соответственно рассчитываются количество итераций и размер согласованного набора . После каждой итерации два значения корректируются, если найден более крупный согласованный набор. Если, например, алгоритм запускается с долей выбросов, равной 50%, а вычисленный консенсусный набор содержит 80% всех точек данных, результатом будет улучшенное значение для доли выбросов, равной 20%. Затем пересчитывается количество итераций и необходимый размер согласованного набора .
пример
Прямая линия должна соответствовать набору точек на плоскости. Точки показаны на первом рисунке. На втором рисунке показан результат разных прогонов. Красные точки поддерживают прямую линию. Точки, расстояние от которых до прямой превышает предел погрешности, окрашены в синий цвет. На третьем рисунке показано решение, найденное после 1000 итераций.
- RANSAC для адаптации прямой линии к точкам данных
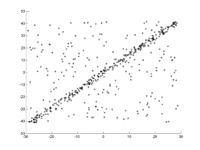
1. Исходный набор данных.
2. Анимация нескольких итераций.
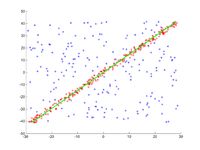
3. Результат после 1000 итераций.



Достижения
Есть несколько расширений RANSAC, два из которых здесь важны.
ЛО-РАНЗАК

Эксперименты показали, что в большинстве случаев требуется больше итерационных шагов, чем теоретически достаточное количество: если модель рассчитывается с набором точек без выбросов, не все другие значения, которые не являются выбросами, должны поддерживать эту модель. Проблема проиллюстрирована на рисунке напротив. Хотя прямая линия была рассчитана с использованием двух правильных значений (черные точки), некоторые другие явно правильные точки классифицируются как выбросы (синие звезды) в правом верхнем углу изображения.
По этой причине исходный алгоритм LO-RANSAC (локально оптимизированный RANSAC) расширяется на шаге 3. Сначала, как обычно, определяется подмножество точек, не являющихся выбросами. Затем модель снова определяется с использованием этого набора и с помощью любого метода компенсации, такого как метод наименьших квадратов. Наконец, вычисляется подмножество, расстояние до которого до этой оптимизированной модели меньше предела ошибки. Только это улучшенное подмножество сохраняется как согласованный набор .
MSAC
RANSAC выбирает модель, которая поддерживается большинством измеренных значений. Это соответствует минимизации суммы, в которой все безошибочные значения вводятся с 0, а все выбросы с постоянным значением:


Расчетная модель может быть очень неточной, если граница ошибки слишком высока - чем она выше, тем больше решений имеют одинаковые значения для . В крайнем случае все ошибки в измеренных значениях меньше, чем предел погрешности, поэтому он всегда равен 0. Это означает, что выбросы не могут быть идентифицированы, и RANSAC дает плохую оценку.
MSAC ( М -Estimator С.А. mple С onsensus) является расширением RANSAC, который использует модифицированную целевую функцию , чтобы свести к минимуму:

С помощью этой функции выбросы продолжают получать определенный «штраф», превышающий порог ошибки. Значения ниже предела ошибки включаются в итоговое значение с ошибкой вместо 0. Это устраняет упомянутую проблему, поскольку вклад точки в общую сумму меньше, чем лучше она соответствует модели.
Индивидуальные доказательства
- ^ Роберт С. Боллс: Домашняя страница в НИИ . ( онлайн [доступ 11 марта 2008 г.]).
- ↑ Мартин А. Фишлер: Домашняя страница SRI . ( онлайн [доступ 11 марта 2008 г.]).
- ↑ Мартин А. Фишлер и Роберт К. Боллс: Консенсус случайной выборки: парадигма подгонки модели с приложениями к анализу изображений и автоматизированной картографии . Март 1980 г. ( онлайн [PDF; 301 кБ ; доступ 13 сентября 2007 г.]).
- ↑ Даг Эверинг: Отслеживание на основе моделей с использованием линейных и точечных корреляций . Сентябрь 2006 г. ( онлайн [PDF; 9.5 МБ ; доступ 2 августа 2007 г.]).
- ^ Мартин А. Фишлер и Роберт К. Боллес: RANSAC: историческая перспектива . 6 июня 2006 г. ( онлайн [PPT; 2.8 МБ ; по состоянию на 11 марта 2008 г.]).
- ↑ Кристиан Бедер и Вольфганг Ферстнер : Прямое определение цилиндров из трехмерных точек без использования нормалей к поверхности . 2006 г. ( uni-bonn.de [PDF; дата обращения 25 августа 2016 г.]).
- ^ Ондржей Чум, Йиржи Матас и Штепан Обдржалек: Улучшение RANSAC с помощью обобщенной оптимизации модели . 2004 г. ( онлайн [PDF; просмотрено 7 августа 2007 г.]).
- ↑ PHS Torr и A. Zisserman : MLESAC: новый надежный инструмент оценки с приложением для оценки геометрии изображения . 1996 ( онлайн [PDF; 855 кБ ; по состоянию на 7 августа 2007 г.]).
литература
- Мартин А. Фишлер и Роберт К. Боллс: Согласие на случайной выборке: парадигма соответствия модели приложениям для анализа изображений и автоматизированной картографии. (PDF, 1,2 Мб) (больше не доступны в Интернете.) 1981, архивируются с оригинала на 5 апреля 2019 года ; Доступ к 14 октября 2019 года .
- Различные авторы: 25 лет RANSAC, Workshop в сочетании с CVPR 2006 2006, доступ к 11 марта 2008 года .
- Питер Ковеси: RANSAC - надежно подгоняет модель к данным с помощью алгоритма RANSAC (реализация Matlab). 2007, доступ к 11 марта 2008 .
- Фолькер Родехорст: Фотограмметрическая 3D-реконструкция с близкого расстояния посредством автокалибровки с проективной геометрией . wvb Wissenschaftlicher Verlag Berlin, 2004, ISBN 978-3-936846-83-6 (университетская публикация, плюс диссертация, Технический университет Берлина 2004).
- Ричард Хартли, Эндрю Зиссерман: Множественная геометрия представления в компьютерном зрении . 2-е издание. Издательство Кембриджского университета, Кембридж, Великобритания, 2004 г., ISBN 978-0-521-54051-3 (английский).
- Тило Струтц: Подгонка данных и неопределенность (практическое введение в метод взвешенных наименьших квадратов и другие аспекты) . Издание 2-е издание. Springer Vieweg, 2016, ISBN 978-3-658-11455-8 (английский).